類神經網路(Artificial neural network)也常被稱為人工神經網路,這個題目有著很多本書厚的艱深,好在今天的難只到厲害的題目名稱,我們今天淺淺的複習R語言幾個類神經網路套件的使用方式然後簡單解釋神經網路架構元素。
因為太抽象不容易理解,自己學習時先想把她想像成是一種模仿人類神經網路結構的演算法,把重點放在網路結構,神經元運算結果能夠彼此分享使得整體結構具有自我學習的能力。架構內主要分成輸入層、隱藏層及輸出層,她可以同時用來預測分類問題以及連續數值問題,不過在機器學習中,通常會把她畫在分類演算法下。
類神經網路主要結構:
好,今天複習R語言當中常用的兩個類神經網路套件nnet()及neuralnet(),我們先準備戰場,專案新增一支Day27.R
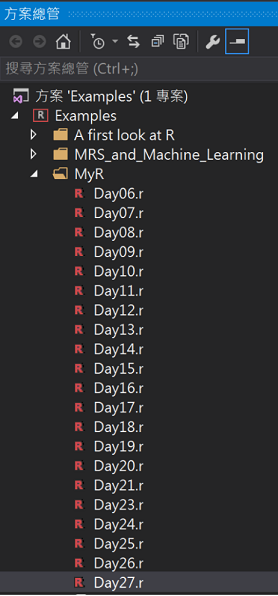
這邊我們使用鳶尾花資料iris集複習。
#(1)載入套件及資料
#從github下載套件 #plot.nnet
source_url('https://gist.githubusercontent.com/Peque/41a9e20d6687f2f3108d/raw/85e14f3a292e126f1454864427e3a189c2fe33f3/nnet_plot_update.r')
library(DMwR)
library(nnet)
library(reshape)
library(devtools)
library(scales)
library(ggplot2)
#範例使用irisdata
data(iris)
#(2)分為訓練組和測試組資料集
set.seed(1117)
#取得總筆數
n <- nrow(iris)
#設定訓練樣本數70%
t_size = round(0.7 * n)
#取出樣本數的idx
t_idx <- sample(seq_len(n), size = t_size)
#訓練組樣本
traindata <- iris[t_idx,]
#測試組樣本
testdata <- iris[ - t_idx,]
nnetM <- nnet(formula = Species ~ ., linout = T, size = 3, decay = 0.001, maxit = 1000, trace = T, data = traindata)
#(3)畫圖
plot.nnet(nnetM, wts.only = F)
#(4)預測
#test組執行預測
prediction <- predict(nnetM, testdata, type = 'class')
#預測結果
cm <- table(x = testdata$Species, y = prediction, dnn = c("實際", "預測"))
cm
單層隱藏層的類神經網路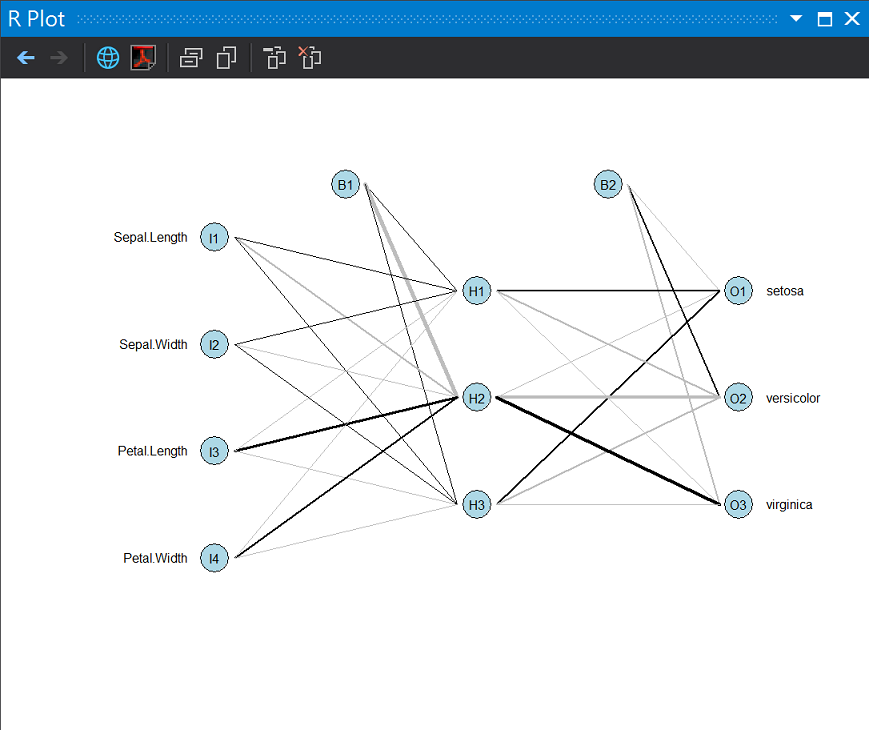
混淆矩陣觀察對角線正確率: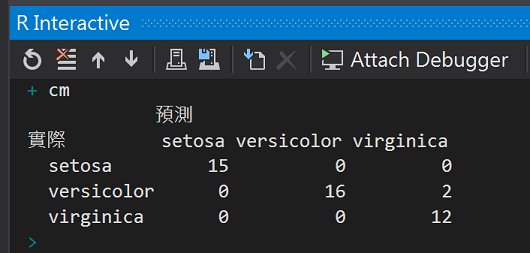
試試看把中間隱藏層的神經元改成6個
nnetM <- nnet(formula = Species ~ ., linout = T, size = 6, decay = 0.001, maxit = 1000, trace = T, data = traindata)
plot.nnet(nnetM, wts.only = F)
#載入套件
library("neuralnet")
#整理資料
data <- iris
data$setosa <- ifelse(data$Species == "setosa", 1, 0)
data$versicolor <- ifelse(data$Species == "versicolor", 1, 0)
data$virginica <- ifelse(data$Species == "virginica", 1, 0)
#訓練模型
f1 <- as.formula('setosa + versicolor + virginica ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width')
bpn <- neuralnet(formula = f1, data = data, hidden = c(2,4),learningrate = 0.01)
print(bpn)
#圖解BP
plot(bpn)
兩個隱藏層,第一層兩個神經元,第二層四個神經元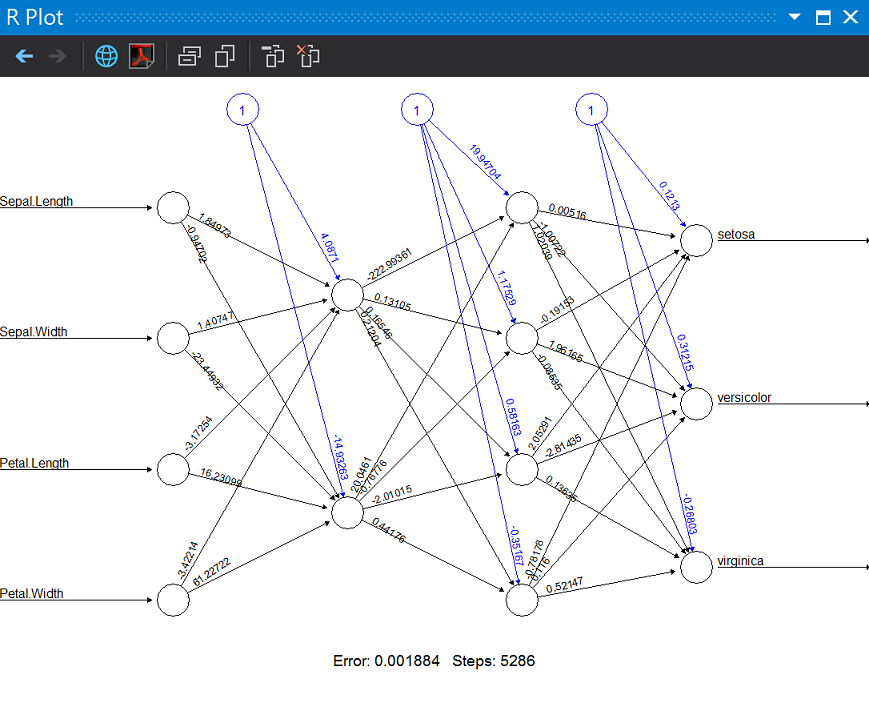
預測結果
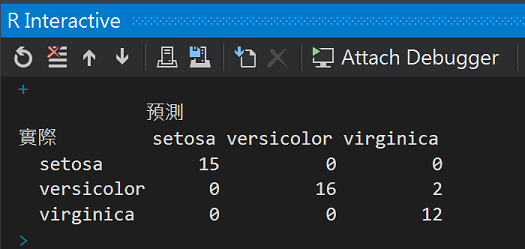
雖然增加隱藏層與神經元數目能強化類神經網路的結構,但如果模型就幾乎把訓練資料的結構記憶,面對新變化的測試資料反而會預測失準,也就是模型過度學習(over fitting),所以除了執行效能考慮,過度學習也是我們考慮隱藏層與神經元數目的重要因素。
除了使用輸入層加上輸出層數目開根號決定單層隱藏層中的神經元數目,多層隱藏層找最佳神經元數目的任務就將給專業的,這邊我們會用caret套件下的train()函式來幫助我們。
#調校參數
library(caret)
#預測最佳神經元參數組合
model <- train(form = f1, data = traindata, method = "neuralnet",
tuneGrid = expand.grid(.layer1 = c(1:4), .layer2 = c(1:4), .layer3 = c(0)), learningrate = 0.01)
model
沒想到最小均方根誤差(RMSE:Root mean square error)的組合是1,1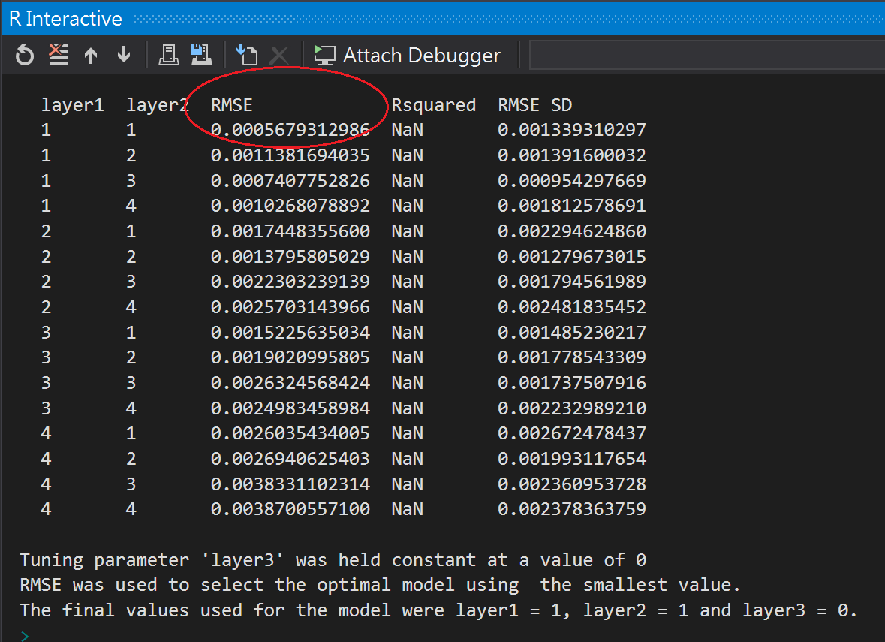
「均方根誤差」(Root mean square error,RMSE) 是統計上的標準方法,用於查看不同資料集的比較方式,然後讓可以透過輸入刻度導入的差異變平滑。
RMSE 代表與實際值相比時,預測值的平均誤差。 它會以所有資料分割案例平均誤差的平方根,除以資料分割中的案例數目來計算,不包括目標屬性擁有遺漏值的資料列。
其他R Package:
人工神經網絡
https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
nnet: Feed-Forward Neural Networks and Multinomial Log-Linear Models
https://cran.r-project.org/web/packages/nnet/index.html
Training of Neural Networks
https://cran.r-project.org/web/packages/neuralnet/index.html
交叉驗證 (SQL Server 資料採礦增益集)
https://msdn.microsoft.com/zh-tw/library/dn282375(v=sql.120).aspx
不同方向的薩爾斯堡

2013-05攝於Salzburg,Austria
您好,我想詢問一下使用neuralent的問題,我目前的操作步驟是這樣的
Step1. 產生一組訓練資料
Step2. 使用neuralent函數
Step3. 產生此資料的類神經網路架構圖(模型)
Step4. 產生一組測試資料,使用caret套件,找出層中最適合的神經元數
我的輸入變數是50個1到100的隨機數字,在神經元為4個,學習速度0.01及門檻值0.01狀況下,想要預測這50個數字的開根號值,所以我的neuralent是設定成這樣的
A <- neuralnet(Sqrt~X1, sqrt.data, hidden=4, learningrate=0.01, threshold=0.01)
接下來我按照您的範例,想要用caret套件,找出最適合的神經元數,不知道是不是因為我只有一層,所以一直出現以下的錯誤
model <- train(form=A, sqrt.data, method = "neuralnet",
tuneGrid = expand.grid(.layer1 = c(1:4), .layer2 = c(0), .layer3=c(0)),
learningrate=0.01)
為了要測試是不是因為我只有單一變數單一層才會出現這樣的問題,所以我想試一下再多設定幾個變數進去,但現在遇到的問題是,我用了同樣的輸入變數(設定一樣的學習速度和神經元),沒有辦法再重新第一次跑出來的結果。不知道您可不可以提供給我一些建議 ︾︾
我們出現的是Warning message而不是Error,所以,也許我們試試打model看一下結果。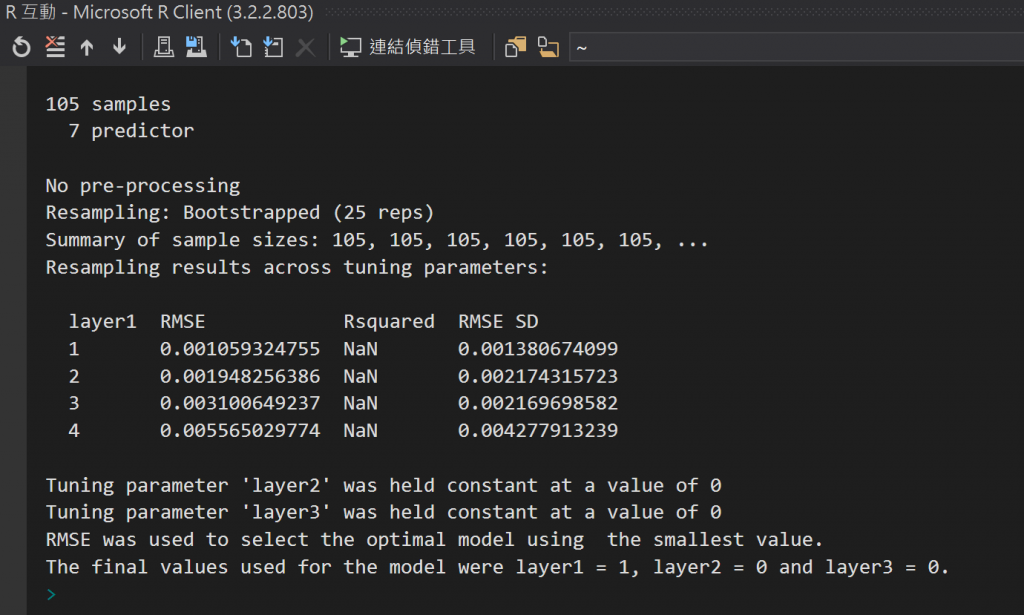
另外,數字開根號的預測,是不是用簡單迴歸就可以解題了?
還是我們只是想練習一下多層隱藏層的類神經網路演算法。



 iThome鐵人賽
iThome鐵人賽